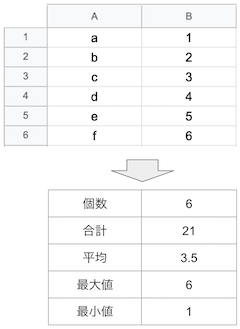
CSV形式のファイルから特定列の個数・合計・平均・最大値・最小値の求め方をまとめました。主にawkを利用して集計します。
個数
行数を知るだけであればwcが楽です。
wc -l sample.csv # result 6 sample.csv
awkを利用すると下記のように集計できます。
awk -F ',' '{c += 1} END {print c}' sample.csv # result 6
列の値が欠けていることがある場合は、それ以外の値で見るようにします。
awk -F ',' '$2!=NULL {c += 1} END {print c}' sample.csv
合計
列の値を加算していきます。2列目は$2です。
awk -F ',' '{s += $2} END {print s}' sample.csv # result 21
平均
合計を個数で割ります。
awk -F ',' '{c += 1; s += $2} END {print s / c}' sample.csv # result 3.5
最大値
値域が分かっている場合は初期値を設定し、その初期値より大きいものを求めていきます。
awk -F ',' 'BEGIN {max = 0} {if (max < $2) max = $2} END {print max}' sample.csv # result 6
値域が分からず初期値を設定できない場合は、配列を作って求めるとかですかね。
awk -F ',' 'BEGIN {i = 0} {arr[i] = $2; i++;} END {max = arr[0]; for (i in arr) {if (max < arr[i]) max = arr[i];} print max}' sample.csv # result 6
最小値
初期値を設定し、その初期値より小さいものを求めていきます。
awk -F ',' 'BEGIN {min = 100} {if (min > $2) min = $2} END {print min}' sample.csv # result 1
初期値の設定をしないやり方です。
awk -F ',' 'BEGIN {i = 0} {arr[i] = $2; i++;} END {min = arr[0]; for (i in arr) {if (min > arr[i]) min = arr[i];} print min}' sample.csv # result 1